
Scaling Backend 100x

The post will show how we scaled a lot of our time-consuming background jobs by 100X and more. Obviously, 100X is relative to where we were before. Our previous post covered some of the optimizations we did earlier and how the setup looks like. For sake of brevity, we won’t repeat that here but briefly mention the setup and DB sizes as of today. We pull data (primarily time series) from hundreds of external sources and store them in our Postgres instance. Since our queries are analytic in nature and require heavy joins, we do roll-ups and precompute those joins and store the denormalized data in MongoDB. Since our previous post on the scale, our Postgres has grown from ~100GB to ~1TB and Mongo from ~40GB to ~160GB and we face scale and performance issues at all stages of our ETL pipeline:
- Ingestion: While ingesting external data into PG,
- Precomp: While computing the rollups data (at daily and hourly level) and pushing to MongoDB
- Querying: While serving our analytics queries
In early January this year, my co-founder got us a new customer who was interested in our product. They are in Europe and a $12 Billion company. This was our first unicorn customer. While we all were super excited to get them on board, our fear was whether our backend will be able to handle their scale. I and my co-founder did a quick back of the envelope calculation. Based on that we concluded that our new customer is more than 100 times bigger than all our existing customers combined! We were jumping in excitement at the prospect of getting such a big customer but the problem was that our backend was in no way ready to handle this scale. Being an enterprise product, the sales cycle is longish (3–6 months), so thankfully we had time before the customer would come onboard fully. We jumped straight to scaling our backend. The goal was clear: we need to scale at least 100X!
What to scale?
As mentioned earlier, we needed to scale all our stages — ingestion, precomp, and querying. All our background jobs are either in ingestion or precomp phase and the querying phase is simply optimizing our Mongo queries. We are a big fan of instrumentation & monitoring and use Datadog and Graphite/Grafana to track job run times and query latencies. That served as a good starting point. All jobs that are taking too long to run were needed to be optimized. Let's start with the ingestion pipeline where we read external data, check what's in our PG and then update the data.
How to scale? — detour

The first thought we had was that Ruby is slow and MRI implementation, in particular, is not geared for true parallelism. In particular, because of GIL, multiple threads in a Ruby process cannot be scheduled on multiple cores — they all run on the single-core on which the process was started. JRuby does not have this limitation and therefore, that seemed a good candidate and standard benchmarks show that it is 3–5X faster than MRI. We then stumbled upon Truffle, which is another implementation of Ruby language and benchmarks show it to be 30X faster than MRI. However, Truffle was quickly ruled out as it is still in active development and is missing key network implementations (like nokogiri gem) that makes it unusable with Rails. So, JRuby, it is, right? But wait, let's take a step back and understand what are we trying to achieve here. Didn’t we answer that question already? We need to scale 100X, period. Still, it is important to go back and answer scale what?
A typical web application involves a DB. And in our case, we have two DBs! CPU is almost never the bottleneck — it is almost always the I/O. Too many DB queries (especially in a loop), waiting for an external service to respond, network calls, reading/writing from/to disk are the real bottlenecks. So even if we make Ruby “faster”, it won’t help in our case (we are a data-heavy company). The benchmarks are not misleading — they are typically for CPU intensive workloads and it is important to understand that before jumping the gun. Also, moving from MRI to JRuby is a non-trivial migration and it was clear that gains will be limited. Hence, we ditched changing our run time environment for Ruby.
A faster Ruby is not going to magically fix a “bubble sort” hiding deep in your code — Sam Saffron in a recent post
Throwing more machines was the other obvious solution. Apart from being an expensive affair, we strongly felt that it was premature as we ought to understand what is causing the slowness in the first place. Therefore, it was time to become morbidly obsessive at taming our background jobs by finding inefficiencies and nuking them.
How to scale? — again
This section will cover a variety of techniques we applied to identify and remove the bottlenecks. Most of them are agnostic to Ruby on Rails and can be applied to other platforms.
Be extremely lazy
As alluded to in the previous section, our bottlenecks were I/O. Let's focus on the ingestion pipeline where we need to fetch data from external APIs, compare the external data with our PG and update PG. Ingestion itself can be broken down into two parts:
- Fetching ad objects and their attributes and dimensions.
- Fetching the ad objects stats, also known as the report jobs.
For channels like AdWords, the number of ad and keyword objects can be huge — 10k-100k per customer. Fetching these many objects say every hour for hundreds of customers can’t scale. We noted that, practically, in any time delta period, only a fraction of objects change. AdWords has the wonderful CustomSyncService API, which tells the change for a given time. We started querying that first to get a list of campaigns, ad groups, and ads that have changed and refresh only those. That gave a huge performance boost as instead of fetching 100% objects, we were fetching only changed objects which typically would not be more than 1% of total data. 100X gain right there! The moral here — be lazy, we mean, really lazy and fetch only that you absolutely need.
Be smart, challenge the status quo, don’t hesitate to undo things
Now switching to reports. AdWords stats data change for up to 30 days. So even if we have fetched data in the past, each day, we need to keep fetching data for the last 30 days. We call it our "backfill job". Our backfill job was giving big headaches as it was supposed to run once every 12 hours and a single run itself was taking 1.5 days (soon after the new unicorn customer added a handful of their accounts). Yes, you heard it right, 1.5 days to fetch all the data. How in the world are we gonna solve it as we were already doing batch reads/writes, running multiple threads — the obvious parallelism had already been implemented?
We then looked at what it was doing. It was fetching data from AdWords, computing the delta between what is between Adwords and our PG and then writing that to the PG instance. During delta computation, we had a sprinkling logic that would uniformly sprinkle the delta data over all rows for any particular day. Consider its legacy code and an approximation to hide all delta being visible in a particular hour. The problem was that for each object and each day, it had to look at least 24 rows and write back the delta to them. So 24 reads and 24 writes. Since anyway it was an approximation and goal of backfill was more to make sure numbers match at the day level and not necessarily at each hour level, we got rid of it and dumped all the delta in the 23rd hour. So now instead of 24 reads and 24 writes, for each object, a single read and write for each day. This single change alone brought down the time from more than 120k seconds to less than 5k seconds (a day has 86.4k second 😃). A full 24X gain! Lessons here: challenge the status quo, understand your DB queries — especially the ones being done in a loop (or nested loop like ours) and see which one of those loop DB queries you can get rid of.
Index in past != index in future
In another instance, we were pulling data from Google Analytics and the job was taking forever to finish even for fetching only the last 2 days of stats. It was supposed to run every hour and it was taking 178k seconds (~2 days) in the worst case. We nailed it to a missing index — even though we had indexes in place, over time the code changed and a new query was no longer using the old index. The old query had columns (A, B, C, D) in its where clause and we had an index on (A, B, D). The new query had (A, B, C, E) in its where clause. We removed the old index and added the common prefix index (A, B, C). Since cardinality of D was more than that of C, by getting rid of the old index, we actually brought down the index size and were able to use it for both types of queries. This simple change brought down the run time to about 1k seconds — a cool 170X+ gain! While tools like PgHero can suggest you missing indexes, it is ultimately to the application builder to really understand what their code is doing and what is the right index to use.
Reduce DB ops, bulk writes
One of our data decoration jobs was taking forever to finish — it won’t finish even in 24 hours. The decoration involves running multiple annotators on each ad object and writing the annotations to PG and Mongo. For simplicity, let's say we have about 10 annotators that need to run on each object. We had the obvious optimizations in place like only run annotators for recently changed objects. The original implementation would run each annotator, generate the mongo op that will update the annotator hash that we had in the Mongo document for the object. The hash in the Mongo document looks like tags: {: } where each annotator rights a single entry (key/value pair) in the hash. The annotators were multi-threaded as clearly there is a lot of I/O involved. Yet the annotator job will take a really really long time to finish (wouldn’t finish even a day). Because the annotator involved reading from PG, writing back to PG and then pushing the changes to Mongo, we thought batching the reads and writes will help and hence we added batched writes both to PG as well as Mongo. Yet this didn’t help — our job will continue running for more than a day and no hope of finishing!
Then we took a closer look at the logs and tried identifying where it was actually getting stuck. Our analysis showed that it was the Mongo writes. The next question was on how can we reduce the number of ops we generate? That immediately gave the idea that we do not need to generate a mongo write for each annotation to each object (corresponds to one mongo document). Instead, run all annotators on the object, write all the changes to PG and then have a single bigger update that updates all the key/value pairs in the hash in Mongo. We also instrumented the total number of ops generated (rather naively by having a log statement showing the number). In our test setup itself, we saw that in a test where earlier it was generating more than 500 ops, after the simple move, the ops reduced to about 50. After this optimization launched, the job that wasn’t finishing at all finished in 10 minutes! Since we did a lot of other batches write optimizations too, it is hard to isolate the exact impact of reducing the mongo ops, but we estimate that overall, we had at least 144X gain (remember the job was not finishing even in a day).
In yet another instance, one of our external API jobs was taking more than a day to finish. We were pulling the last 7 days of data and the time-series file was a JSON file as big as 100MB. The job had to parse the file, accumulate stats in-memory by a group-by key and then write that to DB. The stats are hierarchical in nature — campaigns contain ad groups and ad groups contain ads and each ad has some 20 metrics for each day and OS type. We were already doing batch writes but in order to keep the code simple, we were only batching writes within an ad group. Using stack dump from the live job, we identified that the writes to PG were the bottleneck. We kept wondering why they are taking the time as we were already batching. It then occurred to us that each campaign has about 5–6 ad groups but each ad group has only about 1.2 ads on an average. So even though we were batching writes, the earlier batching was poor. We then started aggressively batching across ad groups and even across campaigns and jobs became at least 5X faster. It still takes 20k seconds to finish — is supposed to run once per day, so kind of ok for now! Interestingly, when it was taking more than a day to finish, it was also hogging as much as 40GB of memory. Now that it has become faster, memory does not peak beyond 5GB.
Hash With Indifferent Access (HWIA) is a murderer
The tag annotator job that we scaled 144X by reducing Mongo ops a month later again became dog slow (about 15X slow). We were really shocked to see that as all the hard work to tame as it seemed to have gone wasted. After carefully looking at all commits, we isolated it to a change that was done with good intention to detect ad objects that have not changed and hence would not require re-annotation. Our initial check was comparing a JSON hash with a symbolized keys Hash. Those who know Ruby will immediately spot that JSON hash will have string keys whereas we were comparing it against a symbolized Hash, so even if they are identical except for key type, it won't match. As a result, we were unnecessarily re-annotating unchanged objects.
One of our engineers spotted that and fixed it in a seemingly innocuous pull request by making the comparison to compare two HWIA hashes instead. While the code was correct, it undid all the gains we made by reducing the Mongo ops. We immediately reverted the change being aware that the change was actually fixing an inefficiency. Post revert, the job was back to its original performant state. Till that time we were liberal with our use of HIWA. Post that traumatic event, we added a check-in Rubocop and overcommit config to prohibit the use of HWIA and religiously went through the code to exterminate HIWA from our code. We still have few places using HWIA but they have been isolated and measures are in place to make sure they don’t multiply! As an aside, 3 months later we fixed the inefficiency correctly by making the check between two symbolized Hashes. That gave another 10X boost for a combined staggering gain of 1440X (Mongo ops optimization plus the bug fix to correctly compare two symbolized Hashes)!
Memoization and caching
We previously mentioned how we got rid of some DB writes and it dramatically improved the performance. It is not always possible to get rid of DB queries. However, it often happens that we are doing the same query again and again in a loop. Note that it is possible that the loop may be invisible i.e. some method may be calling another method and that other methods might be executing the same query based on the passed arguments.
Our CTO, Ashu Pachauri, made a cool observation that we can use SimpleCov hits/line counter to find lines that are repeatedly being called. That turned out to be an awesome insight — we found many places where we could remember the result of DB query either in local memory or storing it in our distributed Redis cache. We identified more than twenty such hotspots. While we don’t have individual improvement numbers, our test suite which used to take as much as 20 minutes, now takes less than 7 minutes (there were some other optimizations too that we did to make our test pipeline faster, reserving that for a future post). That is a huge huge improvement as we already were using Parallel RSpec. For the record, we run our test job on Jenkins with 8 cores, have 670 spec files, 1.7k it blocks and 17k expects and our test coverage is about 75%. Our tests are more like module tests rather than unit tests and as such rely on Postgres and Mongo read/writes. We do use FactoryBot and can’t rely on its in-memory build constructs alone, we need to use create so that our module tests can verify the state of DB and do further processing based on that. Note that the memoizations and caching improvements led to significant improvements in production too — for us being able to bring down our test run time numbers seemed even bigger achievement as it improved developer productivity — pull requests could be iterated on 3X faster now!
Other optimizations
I will briefly mention some of the other optimizations we did. Each has a reference to external sources outlining why it makes sense to do that.
- Freeze all your strings with a magic comment — We wrote a handy script to do it in all 3500+ files across our codebase.
- Replaced ActiveSupport::Cache with Readthis as we rely on Redis heavily for caching — we have 100 databases in Redis with over 13M keys.
- Skip validation during bulk import when using ActiveRecord-import gem — WARNING: do it only when you understand what you are doing.
Query optimizations
So far, all the optimizations were geared towards scaling our background jobs. We also needed to make our real-time queries to Mongo faster. Apart from caching query results in Redis, we noticed that our time series data is sparse — many metrics have zero value and yet we were storing them in Mongo. This was a problem as our documents were becoming bigger and bigger with each day (day level rollups are stored in an array in each Mongo document). A quick calculation showed that by not storing zero metrics in Mongo, we could reduce our document size by as much as 60%. We did exactly that and across our 200+ Mongo collections, we were able to reduce document size from 15%-60%. This was a tremendous gain as Mongo could retrieve the documents much faster.
Beyond this, it was clear that our design of storing time series stats of an object in an array in the Mongo object will lead to document growing indefinitely and making our queries slower and slower each day. Further, Mongo has a hard limit of 16MB for document size. Hence, we can’t allow the doc to grow arbitrarily. This led to the sharding project where each object gets sharded — each shard containing only 6 months of data. This was a big change and a future post will outline how we did it and its implications.
The Impact

In hindsight, the optimizations outlined above may look simple but it took more than 5 months to really scale our backend. The optimizations were not easy to identify and without tools like Datadog where we track per job run times, RubyProf, stackdump, and SimpleCov, it would have been impossible. Super proud of the scale we have achieved in the past 5 months. While we can present endless graphs for each of the individual optimizations we did, we will present a couple of tables — how the run times looked for the worst jobs in January, in May and now (in June). The numbers clearly show how we were able to dramatically improve our bottom line across the board and not just a one-off gain limited to a few jobs.

Worst 50 job run time before optimizations [January 2018] — does not cover jobs that were taking forever to finish as timing metrics are reported only after they finish The above graph only shows the state of affairs in the month of January. Once the unicorn customers channel accounts were integrated (in Feb and beyond), some new jobs started taking days to finish. That is not captured above because Datadog barfs out when we query job run times for longer periods than a month. In May, when we were still in the middle of optimizations, worst job times looked like this:
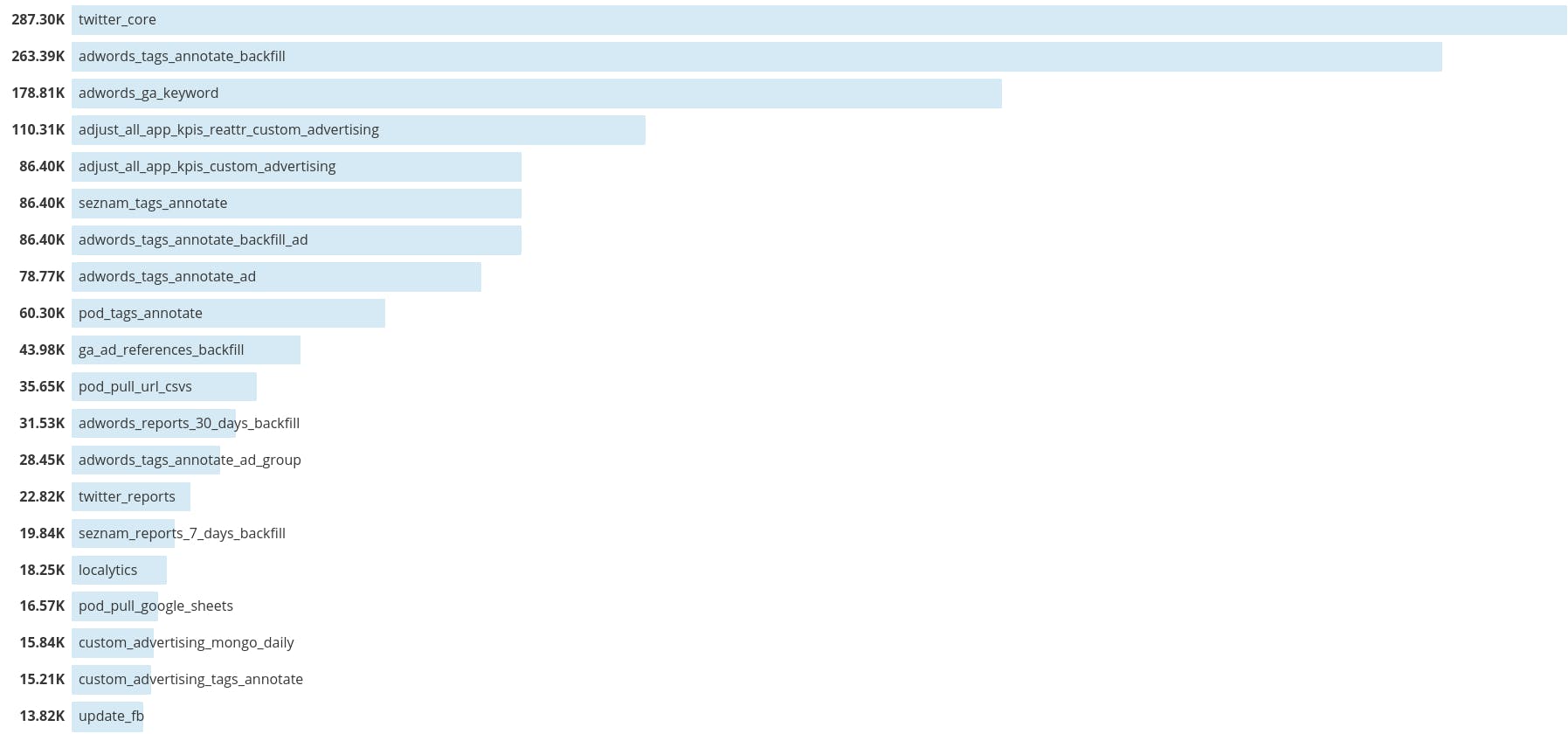
After all the optimizations, our current worst-case times look like this:

The Road Ahead

While we are super proud of what we have achieved so far and thankful to our unicorn customer for pushing us out of our comfort zone, we must admit our setup is still relatively small — we still are talking about few terabytes of data. As more customers come on board, the current choice of MongoDB as our OLAP is not sustainable. There are better alternatives belonging to the class of columnar DBs like Druid, Clickhouse, and BigQuery that are much better suited for analytics queries and can easily scale to petabytes of data and beyond. I would love to brainstorm with folks who have worked with these DBs and/or otherwise have scaled their analytics pipeline to petabytes of data! I can be reached at ankur@clarisights.com. Happy scaling!
Ciao.
PS: If you want your Mondays to be awesome, want to be in a state where you look forward to coming to the office each day and want to solve exciting problems like above then apply here to join our team!