
Lessons, mistakes, challenges building our in-house Orchestrator for Big Data pipelines: A year of learnings developing Mozek
This journal entry is your behind-the-scenes guide on everything new about Mozek, one of our most complex engineering projects at Clarisights.



The Mozek project began in 2022 and has been one of the most ambitious engineering projects we've ever undertaken at Clarisights. We have documented our journey transparently while designing this system through a mini-series called The Mozek Dev Diaries. This is part of our official Clarisight Sessions podcast, which is available on all major platforms where you get your podcast. We just published our latest episode; check it out now!
Episode #4 on Mozek Dev Diaries
If you haven’t had a chance to check it out yet or are looking for reasons to dive in, here’s a short refresher on Mozek.
What Exactly is Mozek?
Clarisights is a self-service enterprise marketing reporting platform. We enable that by bringing together data fetched from hundreds of data sources using millions of data ingestion pipelines into a single unified dashboard. Hundreds of marketers across our global portfolio of customers use Clarisights to get crucial insights into their campaigns without writing any code, data pipeline maintenance, or experts. This data is requested, fetched, and synced by an Orchestrator. A data orchestrator, more specifically, is a system that keeps track of the current state of data and coordinates the data flow within the data ecosystem.
Previously, we used orchestrators available in the market, such as Cron and Airflow. However, there were limitations and significant issues around reliability, visibility, and control while using each system. We needed a system built around control and visibility for our team internally, all the while guaranteeing the sheer reliability that we require from our data processing workloads at scale. These workloads are essential for making the data available for our customers for seamless analysis and decision-making.
Behind the Scenes: Major Work in Progress
Building Mozek has been nothing short of a journey for our team.
The engineering effort to architect this system from scratch has been monumental. The team identified design flaws and customer friction to resolve limitations rooted in the previously used orchestrators. After all, we were building a brain!
Improving reliability
Typically, these reliability issues arise when the orchestrator misses a data unit or a data unit gets dropped somewhere in the pipeline. Even a single unit missing out of millions of data units being processed daily could cause tracking errors. This can happen due to intermittent or extended failures in any part of the system involved in the orchestration or Extract, Transform, and Load (ETL) processes done to the data. A major drawback in existing systems was the missing guarantee that the system would auto-recover as soon as issues were resolved with the data.
This missed data unit leads to data holes. These data holes often persist until our customer success team or our customer notices data gaps and flags them to the engineering team. Identifying the missed data unit, refilling the data hole that has been created, and resolving it are manual, tedious, and cost-intensive processes. Furthermore, in the case of partial failures, the data discrepancies might not even become readily apparent.
If the system takes too long to recover, that leads to further delays in the availability of fresh data. The internal teams often have to take corrective measures to fix the data state manually. Over and over again. No one likes that. Hence, the team came together to make a conscious decision not to shift goalposts any longer, stop hot patching, and instead work to eliminate this problem altogether.
Capabilities of Mozek: Our promise to our customers
Mozek is an orchestration layer that operates with data freshness rules defined by the user. Mozek is fault-tolerant by default and can react to data issues quickly and automatically.
Suppose the data is irrecoverable (e.g., in case of user permission issues). In that case, Mozek keeps the blast radius to the smallest possible number of affected data units instead of creating a big data hole. Going beyond prevention, when the underlying “irrecoverable” error gets fixed, Mozek automatically identifies the fix and fills in the data hole left due to the error, resolving the issue altogether. Total recovery of the data is guaranteed every time. Mozek, as a system, delivers on the promise of data availability to our customers.
This was not a straightforward task and understandably had to take time. We consider Mozek not to be a standalone product but rather a critical foundation for our business model. The very same foundation our customers rely on, for even their businesses. Getting every element of our product right is always a massive priority for the team.
Mozek Deployed to Production
In the last 18 months, Mozek has undergone intensive testing and development cycles. It was then deployed for Clarisights’s biggest data channels: Google Adwords & Facebook.
Being the biggest data source meant that most of the data pipeline incidents were caused by these sources running on the current sub-optimal orchestrator. The team had to routinely resolve customer issues and on-call incidents that stalled development & dug new rabbit holes. All these factors contributed to the team's choice to migrate these data sources to Mozek first. Here's the impact Mozek has made for just one of our customers before and after we migrated Adwords to Mozek for them.
Before the migration of Google Ads and Facebook, these were the busiest channels with the most significant number of customer-reported on-call issues. After moving them to Mozek, that trend dropped to one-off instances where our customers reported an issue.
Every time the data gets synced on Clarisights, it's Mozek behind the scenes running the show & making sure the data is reliable, available, and accurate.
Our Results: Exceptional Performance & Reliability Improvements
After deployment, our ETL pipelines team reported almost no incidents on data sources where Mozek had been running for several weeks. The difference seemed like day and night. Mozek now effectively frees our team's time to focus on new projects instead of constantly putting out fires in the data pipelines.
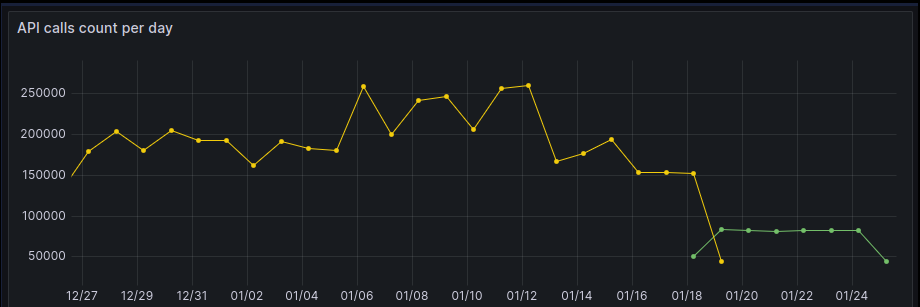
The effort behind improving Mozek has led to a 50% reduction in database writes and cost savings across the board. We also see a significant 65% reduction in total API calls our backend makes to different data sources, such as Google Ads and Facebook, which were moved to Mozek. This reduces the data bandwidth consumed and frees up resources as we cull the excess.
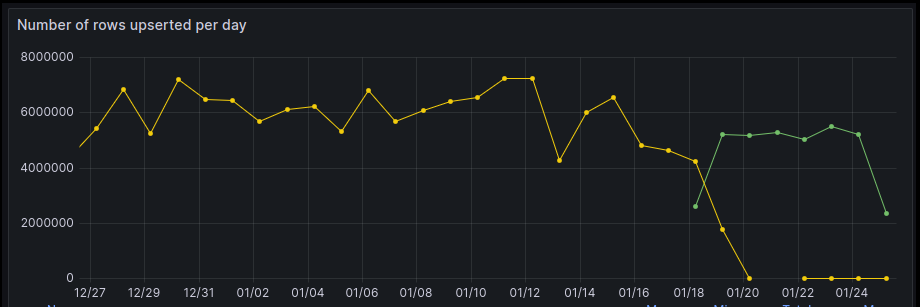
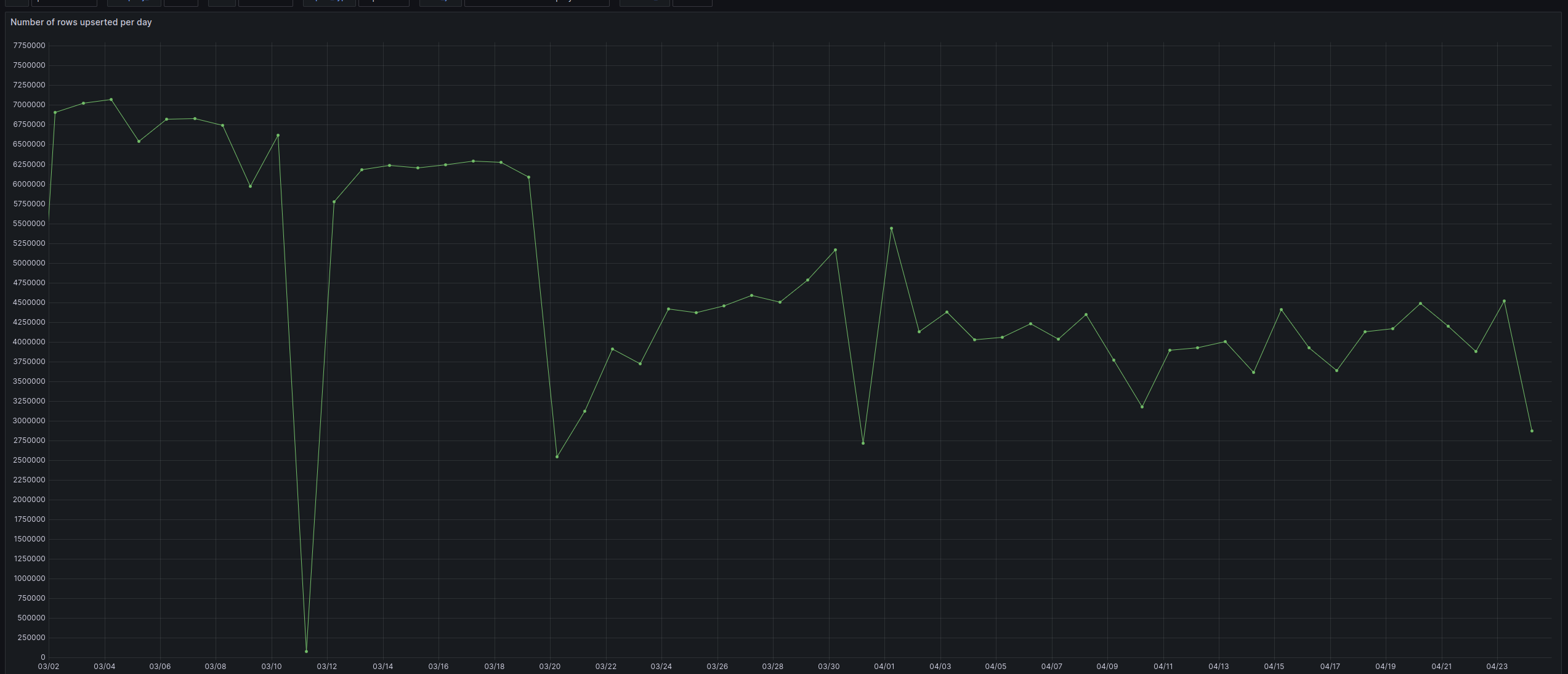
The team actually identified that the initial improvements in Facebook surveys were below their expectations. After an investigation and detailed review of the pipeline, we found that there was a bug identified on Facebook regarding this information. The team has resolved it, and the upserts dropped further in FB (see next graph). A design change is planned in the rule system to reduce redundant task processing and reduce upserts further.
Continuous Time Project: Solving for Data Uncertainty
The Continuous Time (CT) Project is the next version of the orchestrator. The team is looking to solve fundamental failures plaguing every data orchestrator available in the market. These failures include losing data state or inadvertent data holes due to system downtimes.
The CT Orchestrator in Mozek solves these issues by accounting for all variables possible in the system before starting the decision-making process. The CT Orchestrator ensures no data unit gets missed in its decision-making process and enables automatic data recovery in case of long-term failures.
For example, say there was an authentication issue with a customer’s account or the account was inactive for several months. With the old orchestrator, the team would have to step in, figure out the data hole, and manually pull the data after the account became active again, which takes time and serious effort. This leads to more extended unavailability of data even after the root cause of the long-term failure or inactive accounts is resolved, leading to customer frustration.
As Murphy's law proposes, anything that can go wrong would go wrong again. Mozek will now be able to handle these scenarios gracefully. With CT Orchestrator, as soon as the root cause gets fixed, Mozek can reconcile the data without any human intervention. The CT Orchestrator also maintains the freshness state of data, which could be leveraged to provide concrete visibility on the data updates to our customers.
With this, Mozek not only becomes reliable and fault-tolerant to these kinds of failures but also provides our customers with unrivaled visibility for their data pipeline at every point.
The Road Ahead for Mozek
While a lot of work has been done on Mozek to build it where it is now. We still have a lot of ground left to cover. The feedback and the reliability gains from both the customers and our team have been positive indicators that we are on the right path. The team’s desire to uncover all design issues, fix edge cases, and solve customer friction has led us here. We are not looking to stop now; instead, we will use this promising new foundation to create a new standard in orchestration for big data pipelines.
One of the next big projects we are taking on with Mozek is Data Service Level Agreements, Tracking, and Alerting. We thought of this as our end goal to guarantee data availability from data sources by a particular time, irrespective of circumstances. At the moment, rules can dictate the freshness of the system, i.e., when the data can be considered not fresh, and for automatic data reconciliation, this works well in Mozek.
These are a few scenarios that can still happen that are beyond the orchestrator's control. Scenarios include pipelines breaking down, data sources having incidents or resource contention occurring across data sources and customers. In these cases, defining just the data freshness conditions is insufficient to ensure their availability as expected by our customers.
To solve the data uncertainty in such cases, Mozek needs to get smarter. We want Mozek to accept user-defined data SLAs. It should be able to figure out the global optimum SLA for every data source. It should also be able to dynamically manage resources in the system as needed to honor SLAs. This is still in the works, and we will share more updates soon.
Building Mozek has been a tough but fun learning experience. Check out our latest podcast episode hosted by Vipul Gupta on Clarisights Sessions to hear more about the exciting new developments the Mozek team from Vijay Kumar & Ashu Pachauri has in store for us.
Episode #4 on Mozek Dev Diaries
Mozek evolved, & so did our team
Much like our thinking while building Mozek, our team at Clarisights has also gone through an evolution. Our in-house team has grown exponentially this past year and has taken ownership of all things Mozek. We look forward to continuously growing our team and are also currently hiring. Come along to solve our mission of democratizing data in enterprise marketing teams.