
The Μμ You Know... (Building a Micro-Chunking Engine for Performance Marketing Data)
How we built a micro-chunking engine to process billions of marketing data rows in minutes instead of hours.


At Clarisights, we're constantly pushing the boundaries of what's possible with data processing to deliver actionable insights to our customers. One of our most significant engineering achievements has been the development of Μμ, a data processing system that has dramatically improved our data ingestion speeds. In this story, we'll take you behind the scenes of how our engineering team, led by Prashant Vithani and Neel Maitra, approached this challenge with a design-first mindset, ultimately landing on Apache Spark and Scala as our technology stack.
Headlines
- Customer data grew to billions of rows
- Reports began to slow down
- Challenge: How to scale data ingestion speeds 10x...
- ... while maintaining transparency and debuggability for marketers
- Idea: Μμ, a micro-chunking engine using Scala and Apache Spark
- Result: Processing time for 1.25 billion rows cut to 7 minutes
The Challenge of Scale...Processing Data at Volume
Performance marketing analytics at scale presents unique data challenges. Enterprise marketing platforms must be able to ingest, process, and analyse billions of rows of advertising data efficiently to provide actionable insights in near real-time.
As Clarisights grew with our enterprise customers, we recognised the need to build systems that could handle increasingly massive datasets with greater efficiency. Our customers run sophisticated marketing operations across multiple platforms, generating datasets that would routinely reach billions of rows. Processing this volume of data efficiently is critical to our value proposition, as marketers need insights quickly to optimise their campaigns effectively. The origins of the Μμ project stem from this scaling requirement—developing the capability to process exponentially more data in significantly less time.
So, the engineering challenge was clear: we needed to develop a system that could scale horizontally with our customers' growing data needs, processing marketing datasets orders of magnitude faster than what was previously possible.
Beyond Speed
When we decided to tackle this problem, we realised we needed more than just a faster system. We took a holistic approach, gathering requirements from our customer success and solutions engineering teams who interact with customers daily.
Speed was, of course, a primary goal, but visibility and debuggability were equally important. Ideally, the customer should be aware of what is happening with their data so they can troubleshoot problems themselves.
This user-centric focus is vital when building a SaaS product. It's not enough for the system to work; customers need to see that it's working and understand what's happening at each stage of the process. This is particularly important for performance marketers, who often need to debug discrepancies in their data or understand why metrics might change over time.
We outlined several key requirements for our new system:
- Dramatically improved processing speed
- Support for incremental processing
- Visibility into the pipeline for customers
- Ability to handle the unique transformations needed for marketing data
- Scalability to accommodate growing data volumes
Design-First: Solving the Right Problem
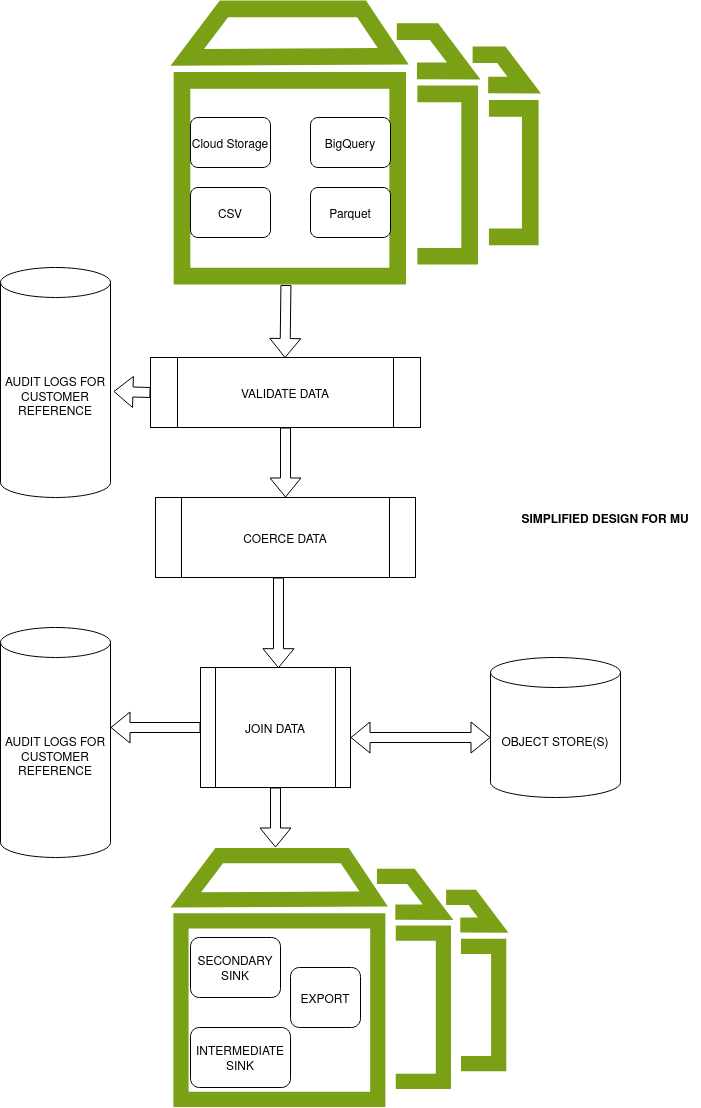
A key differentiator in our approach was starting with conceptual design rather than jumping straight to technology selection. We focused on solving the problem correctly before considering specific tools. And if the right tool didn't exist, we were prepared to build it ourselves.
This design-first philosophy allowed us to fully understand the problem space before committing to specific technologies. We outlined:
- The conceptual design independent of any specific tool
- Requirements and non-goals to focus our efforts
- The need for visibility at each stage of the pipeline
Only after this comprehensive design phase did we start evaluating specific tools and technologies.
A question we often get is: "Why build a custom system when there are established tools like DBT, Fivetran, and Snowflake available?" This is a fair question, and the answer lies in the specific requirements of performance marketing data processing.
Standard ETL tools like DBT have limited support for incrementality. While DBT has introduced some form of incremental processing, it's extremely limited and primarily works with append-only data. Modifying existing data - which is common in performance marketing as metrics update over time - isn't well supported.
Also, the incremental features that do exist in these tools don't support all types of SQL operations. Complex transformations, like the ones needed for marketing data, often fall outside the supported capabilities.
What happens in practice with tools like DBT is that when there's any change in source data, the entire downstream pipeline needs to be reprocessed. This creates a cascade effect where minor changes trigger complete rebuilds of the data warehouse, which is extremely inefficient and expensive.
For performance marketing data, which is constantly updating and requires complex transformations, this approach doesn't scale. The cost of running these operations would be prohibitive, and the processing time would be too long for interactive analysis.
Anyone remember Map-Reduce?
Fun fact: Μμ's design was pretty much directly inspired by the old school idea of a Map-Reduce engine.
What is Map-Reduce? It's a programming model designed to process large datasets across multiple computers. Think of it like an assembly line for data:
- First, in the "Map" step, the data is broken down into smaller chunks that can be processed independently (like dividing a large task among many workers)
- Then each chunk is processed in parallel
- Finally, in the "Reduce" step, all the processed chunks are combined to create the final result
This approach is perfect for our performance marketing data challenge because it allows us to divide billions of rows into manageable chunks that can be processed simultaneously rather than one at a time.
In fact, one key factor that influenced our choice of Spark was the realisation that what we needed was essentially a Map-Reduce system with two modern improvements: in-memory processing (keeping data in memory rather than writing to disk between steps) and persistent data frames (reusable data structures that maintain their state between operations).
Apache Spark
When evaluating technologies, we considered both immediate needs and long-term implications. For example, when selecting a technology like Spark, you're not just choosing a single tool – you're committing to an entire ecosystem. This includes the programming language, build systems, deployment frameworks, and monitoring solutions that work together cohesively. Making the right ecosystem choice is just as important as selecting the right core technology.
We identified two primary candidates:
- Apache Spark: A distributed computing system for large-scale data processing
- Dask: A flexible Python library for parallel computing
While Dask provided more granular control, Apache Spark offered a more complete ecosystem with better abstractions that allowed us to focus on solving our specific problem rather than managing the underlying distributed computing details. Spark doesn't give as much control as Dask does, but it hides a lot of things behind the interface that gives you flexibility to focus on the problem at hand.
Apache Spark, though not a new technology (it's over a decade old), was the right choice for Μμ for several reasons. Spark is a mature, battle-tested framework for large-scale data processing, offering:
- Distributed Computing: Spark allows operations to be parallelised across multiple machines, enabling us to process large datasets quickly.
- In-Memory Processing: Unlike earlier Map-Reduce implementations that write intermediate results to disk, Spark keeps data in memory whenever possible, dramatically improving performance.
- Rich Ecosystem: Spark comes with libraries for SQL, streaming, machine learning, and graph processing, giving us a comprehensive toolkit for various data operations.
- Fault Tolerance: Spark provides mechanisms to recover from node failures, ensuring reliability in production environments.
- Optimisation Engine: Spark includes a query optimiser that can automatically improve the efficiency of operations.
Even though Spark has been around for a while, we weren't just using it off-the-shelf. The real innovation in Μμ came from how we applied Spark to the specific challenges of performance marketing data – particularly the need for incremental processing and the unique transformation requirements of marketing data.
Language Selection: The JVM Question
Once we decided on Apache Spark, we needed to choose a programming language. Spark supports multiple languages, including Java, Python, and Scala. This decision was critical because it would influence not just Μμ itself but potentially the entire data ingestion framework.

Python was quickly eliminated. Since Spark runs on the JVM, using Python would require translation between the languages, creating an additional layer of complexity for debugging.
Between Java and Scala, we chose Scala because:
- Spark itself is written in Scala
- Scala runs natively on the JVM, eliminating translation issues
- As a functional language, Scala provides elegant abstractions for data processing
We were able to translate an initial prototype from Clojure to Scala in just two weeks, including the time spent learning the language.
Μμ means "micro"...
With the technology decisions made, we set out to build Μμ. Μμ is a Greek letter which stands for ‘micro’. And that's basically how the project functions, by splitting tasks into micro chunks and executing each chunk in parallel leading to greater speed and efficiency into the system.
This approach mirrors our work on other foundational systems like MorselDB, where we've taken a chunk-based approach to data processing. You could say our engineering philosophy is to take small bites in parallel, which directly contradicts the philosophy of lunchtime at the office where big bites rule the day.

This approach directly addressed the fundamental limitation of our previous row-by-row processing method, leveraging the distributed computing capabilities of Apache Spark. Importantly, the system also improved visibility into the data processing pipeline, allowing customers to better understand and troubleshoot issues with their data. It was also important that Μμ's design could integrate with our existing systems.
The impact of Μμ on our data processing capabilities has been nothing short of transformational. What would have once taken a day, Μμ can accomplish in an hour. During benchmarking, we tested Μμ with a dataset containing 1 billion rows. The system was able to filter 1.25 billion rows in just seven minutes - a task that would have been impossible with our previous architecture.
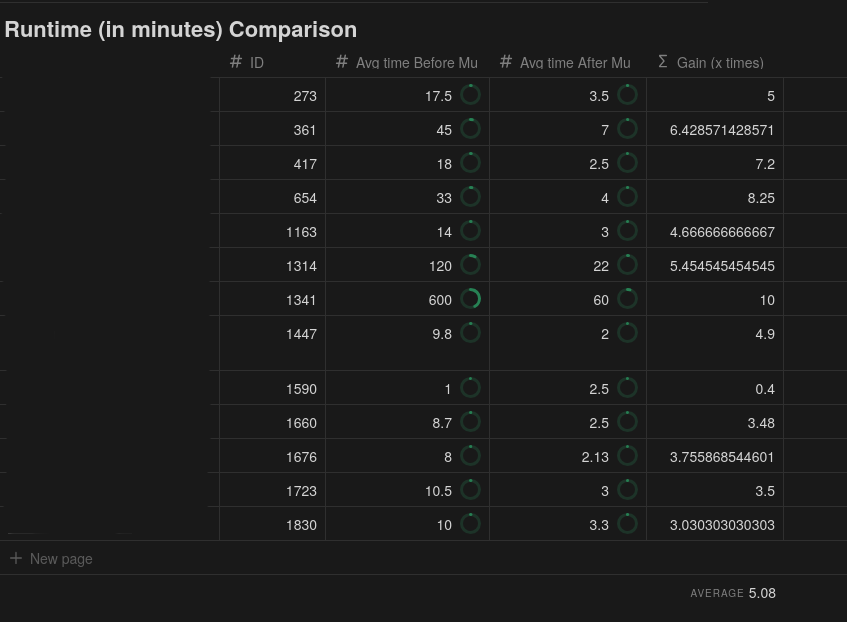
Results...
The impact of Μμ for our customers has been transformative. Taking processing times from days to minutes represents a step-change in how marketers can interact with their data through our platform...
Improved Data Freshness
One of the most significant benefits of Μμ is the improvement in data freshness. Every single day, we pull in data, and we process it. If we could shorten that processing time from twenty-four hours to, say, four hours, the lag instantly drops. The freshest version of the data is available to the user twenty hours earlier. This improvement in freshness is critical for performance marketers, who need to make decisions based on the most current data possible.
Enhanced Interactive Analysis
By supporting incremental processing, Μμ enables marketers to interactively explore their data. When a user modifies a formula or changes how they want to analyse their data, they can see the results quickly without waiting for a complete reprocessing of the dataset. This encourages experimentation and deeper analysis.
Better Visibility and Debuggability
Μμ provides comprehensive visibility into the data processing pipeline, allowing customers to see exactly what's happening with their data at each step. If there are issues or discrepancies, users can pinpoint where they occurred and troubleshoot them directly, without needing to involve our customer success team. This transparency is particularly valuable in the performance marketing context, where understanding why metrics change or how attribution works is critical to optimising campaigns.
Cost Efficiency
By processing data incrementally and in parallel, Μμ significantly reduces the computational resources required. This translates to cost savings that we can pass on to our customers. Traditional approaches that reprocess entire datasets for each change are extremely resource-intensive and expensive at scale. Μμ's efficient processing means we can handle larger datasets for more customers without proportional increases in infrastructure costs.
Empowering Users
Perhaps the most important benefit is how Μμ empowers our users. By making data processing faster and more interactive, we enable marketers to take control of their data without needing to rely on technical teams. They can modify formulas, explore different analyses, and debug issues themselves - truly owning their data and the insights they derive from it.
As we continue to scale and serve more customers with increasingly complex data needs, the foundations we've built with projects like Μμ will enable us to deliver insights with speed and precision that wasn't possible before. If you are interested in working on projects like this one, we are hiring.